
Choosing the Right Model for Your Data
Picking the wrong regression model is one of the most common and most damaging mistakes in quantitative research. And it usually happens not because the researcher does not care, but because the choice between linear and logistic regression seems less important than it is. Both involve regression. Both have predictors. Both produce output. So, what is the big deal?
The big deal is this: these two models answer fundamentally different questions. Use the wrong one and your entire analysis, no matter how carefully executed, rests on a broken foundation. This guide will make sure that never happens to you.
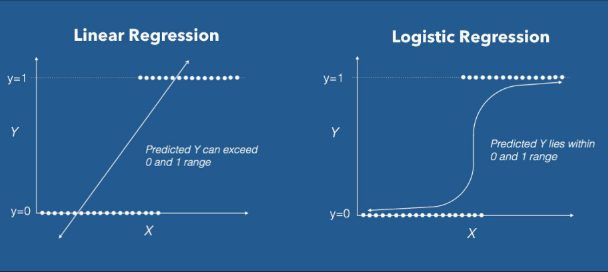
Linear regression predicts a number. Logistic regression predicts a probability.
That single distinction drives every other difference between the two models their assumptions, their outputs, their interpretation, and the kind of research questions they are designed to answer.
If your dependent variable is something you can measure on a scale income, temperature, test scores, GDP linear regression is your starting point. If your dependent variable is a category whether someone defaults on a loan, whether a patient survives, whether a student passes or fails logistic regression is what you need.
Common mistake: Many researchers use linear regression with a binary outcome (coded 0 and 1) because it is simpler. This is technically wrong. Linear regression can produce predicted probabilities above 1 and below 0, which are mathematically impossible. Always use logistic regression for binary outcomes.
Understanding Linear Regression
Linear regression models the relationship between one or more predictors and a continuous outcome variable. It fits a straight line (or hyperplane in multiple dimensions) through the data that minimises the sum of squared residuals — the difference between what the model predicts and what actually happened.
The equation
Y = a + b1X1 + b2X2 + … + bnXn + e
Where Y is your continuous outcome, a is the intercept, b values are the slope coefficients, X values are your predictors, and e is the error term.
What the output tells you
Each coefficient b tells you how much Y changes for every one-unit increase in that predictor, holding all other predictors constant. This is a direct, intuitive interpretation — one that your thesis readers will understand without needing a statistics background.
Key assumptions
1. Linearity: The relationship between X and Y must be linear.
2. Independence: Observations must be independent of each other.
3. Homoscedasticity: The variance of residuals must be constant across all levels of X.
4. Normality: Residuals should be approximately normally distributed.
5. No multicollinearity: Predictors should not be highly correlated with each other.
Example research questions for linear regression
What is the effect of study hours on exam scores?
How does advertising spend affect monthly revenue?
What is the relationship between age and blood pressure?
Understanding Logistic Regression
Logistic regression models the probability that an observation belongs to a particular category. Rather than fitting a straight line, it fits an S-shaped curve (called the sigmoid function) that maps any input value to a probability between 0 and 1.
The equation
log(p / 1-p) = a + b1X1 + b2X2 + … + bnXn
The left side, log(p / 1-p), is called the log-odds or logit. It transforms a probability into a value that can range from negative infinity to positive infinity, which is what makes the linear equation on the right side valid.
What the output tells you
Logistic regression coefficients are interpreted in terms of log-odds, which most people find unintuitive. The standard practice is to exponentiate them into odds ratios, which are easier to communicate. An odds ratio above 1 means the predictor increases the likelihood of the outcome. An odds ratio below 1 means it decreases it.
Tip: In your thesis results section, always report both the log-odds coefficient and the exponentiated odds ratio. Odds ratios make your findings accessible to a broader audience including non-statisticians.
Key assumptions
1. Binary outcome: The dependent variable must be categorical (binary logistic) or ordinal (ordinal logistic).
2. Independence: Observations must be independent.
3. No multicollinearity: Predictors should not be highly correlated.
4. Large sample: Logistic regression needs a reasonably large sample. A common rule is at least 10 events per predictor.
5. No extreme outliers: Influential outliers can distort the model significantly.
Example research questions for logistic regression
What factors predict whether a student passes or fails an exam?
Does smoking status predict the probability of developing a disease?
What variables predict whether a customer will churn?
Side-by-Side Comparison
| Feature | Linear Regression | Logistic Regression |
| Outcome variable | Continuous (e.g. salary, score) | Categorical (e.g. yes/no, pass/fail) |
| Output | Predicted numeric value | Probability (0 to 1) |
| Equation | Y = a + bX | log(p/1-p) = a + bX |
| Assumption | Normally distributed residuals | Binary or ordinal outcome |
| Error measure | RMSE, R-squared | Log-loss, AUC-ROC |
| Interpretation | One unit increase in X changes Y by b | One unit increase in X changes log-odds by b |
| Example use | Predicting house prices | Predicting loan default (yes/no) |
How to Choose: A Decision Framework
Before you run any model, ask yourself three questions in order. The answers will tell you exactly which regression to use.
Question 1: What type of variable is your outcome?
This is the most important question and the answer almost always decides the model. If your dependent variable is continuous and numeric, start with linear regression. If it is binary, nominal, or ordinal, use logistic regression.
Question 2: What is your research question asking?
How much and by how much are linear regression questions. Will it happen and what is the probability are logistic regression questions. If your thesis asks whether certain factors predict the likelihood of an event, you need logistic regression regardless of how the data is coded.
Question 3: What does your data distribution look like?
Even with a continuous outcome, if your data is heavily skewed or bounded (for example, proportions that only range from 0 to 1), a standard linear model may not be appropriate. Similarly, if your outcome is count data, a Poisson regression may be more suitable than either.
Use this quick-reference table when making your decision:
| Situation | Use Linear | Use Logistic |
| Outcome type | Continuous numeric | Binary or categorical |
| Research question | How much? By how much? | Will it happen? What is the probability? |
| Residuals | Normally distributed | Not required |
| Predicted values | Any number | Between 0 and 1 |
| Model fit measure | R-squared | Pseudo R-squared, AUC |
Running the Models: Code Reference
Linear regression in R
model_linear <- lm(outcome ~ predictor1 + predictor2, data = dataset)
summary(model_linear)
Logistic regression in R
model_logistic <- glm(outcome ~ predictor1 + predictor2,
data = dataset, family = binomial)
summary(model_logistic)
exp(coef(model_logistic)) # Convert to odds ratios
Linear regression in SPSS
Analyze > Regression > Linear > Move outcome to Dependent, predictors to Independent
Logistic regression in SPSS
Analyze > Regression > Binary Logistic > Move outcome to Dependent, predictors to Covariates
In Stata
regress outcome predictor1 predictor2 // Linear
logit outcome predictor1 predictor2 // Logistic
logistic outcome predictor1 predictor2 // Logistic with odds ratios
How to Report Results in Your Thesis
Reporting linear regression
A multiple linear regression was conducted to examine the effect of study hours (X1) and attendance rate (X2) on final exam scores (Y). The model was statistically significant, F(2, 147) = 34.21, p < .001, and explained 31.8% of the variance in exam scores (R-squared = .318, adjusted R-squared = .309). Study hours emerged as a significant predictor (b = 4.32, SE = 0.61, p < .001), indicating that each additional hour of study was associated with a 4.32-point increase in exam scores.
Reporting logistic regression
A binary logistic regression was performed to assess the predictors of exam pass or fail. The model was statistically significant, chi-square(2) = 47.83, p < .001, and correctly classified 78.4% of cases. Study hours significantly predicted pass or fail status (b = 0.87, SE = 0.19, p < .001, OR = 2.39), suggesting that each additional hour of study was associated with 2.39 times greater odds of passing.
Pro tip: Always report model fit statistics, individual predictor statistics, and effect sizes together. Reporting just p-values without coefficients or effect sizes is no longer considered acceptable in most academic journals and thesis committees.
Conclusion
Choosing between linear and logistic regression is not a matter of preference or convenience. It is a matter of alignment between your research question, your data type, and your model. Get this wrong and the rest of your analysis no matter how carefully executed is built on a cracked foundation.
The rule is simple: continuous outcome means linear regression. Categorical outcome means logistic regression. When in doubt, go back to your research question and ask what it is actually trying to predict. The answer is almost always in the question itself.